MiniMax发布开源混合架构推理模型M1
article/2026/2/7 20:26:16
6月17日,上海AI独角兽MiniMax正式开源推理模型MiniMax-M1(以下简称“M1”)。MiniMax称,这是全球首个开放权重的大规模混合注意力推理模型。凭借混合门控专家架构(Mixture-of-Experts,MoE)与 Lightning Attention 的结合,M1在性能表现和推理效率方面实现了显著突破。实测数据显示,M1系列在长上下文理解、代码生成等生产力场景中超越多数闭源模型,仅微弱差距落后于顶尖闭源系统。
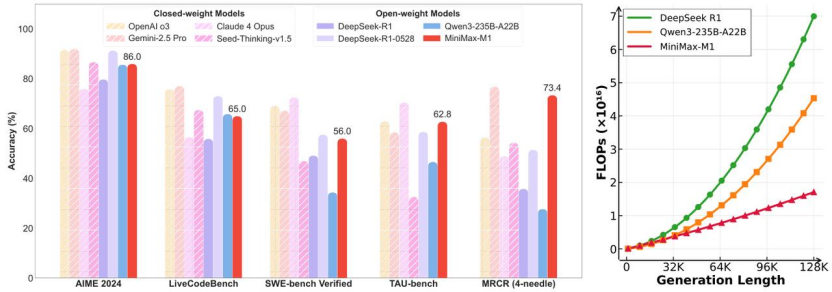
开源报告截图 来源:MiniMax提供
M1支持目前业内最高100万token上下文输入,同时支持最多8万token输出。成本表现方面,在进行8万Token的深度推理时,M1所需的算力仅为DeepSeek R1的约30%;生成10万token时,推理算力只需要DeepSeek R1的25%。MiniMax表示,M1整个强化学习阶段只用到512块H800三周时间,租赁成本为53.74万美元。
天使投资人、资深人工智能专家郭涛向澎湃科技(www.thepaper.cn)分析认为,目前国内大模型市场格局早已形成,大模型竞争不仅仅是技术的竞争,而是算力、数据、应用场景等整个生态的竞争。此次MiniMax更新填补了开源领域长上下文技术的空白,更以“开源+场景化”路径打破技术垄断,为国产大模型迈向实用化树立新标杆。
责任编辑:宦艳红
图片编辑:施佳慧
校对:刘威
相关文章

竞彩湃|国际米兰首战慢热大胜存疑,多特蒙德顺利赢球
周二004 世俱杯弗鲁米嫩VS多特蒙德竞彩SP数据5.28 4.15 1.43+1 2.42 3.65 2.26弗鲁米嫩塞目前巴甲排名第六,南美球会杯也排名小组第一出线,老中卫蒂亚戈席尔瓦领衔球队,中前场年轻的本土球员马丁内利和哥伦比亚国脚攻击手阿里亚斯是比较出名的球员,但整体来说球…

“轮选49”创黄淮海北片优质强筋小麦高产纪录,亩产突破800公斤
6月16日,澎湃新闻(www.thepaper.cn)从中国农业科学院获悉,中国农业科学院作物科学研究所与石家庄市农林科学研究院合作育成的强筋高产广适多抗小麦新品种“轮选49”日前在山东德州、滨州千亩示范方实打验收。本次实收测产依据农业农村部相关测产办法执行,累计收获面积140.…

韩国前总统尹锡悦第三次拒绝警方传唤调查要求
当地时间17日,韩国前总统尹锡悦向警方发送了第三次传唤调查不出席事由书。尹锡悦 资料图韩国警方本月12日第三次要求尹锡悦以嫌疑人身份到案接受调查,负责调查紧急戒严事件的韩国警察厅国家调查本部特别调查团此前表示,警方认为必须对尹锡悦进行面对面的调查,因此再次向他发…

一个伤心脏的坏习惯,你可能每天都在做
原创 丁香医生 不卖关子了,这个坏习惯就是—— 不 刷 牙 是不是觉得不可思议? 毕竟牙刷和口腔卫生绑定得太深了(就像丁香医生对你的爱那么深),以至于一提起不刷牙,大家下意识想到的就是蛀牙、牙周炎等口腔疾病,而忽略了不刷牙可能会给身体带来其他的负面影响。 实际…

莱布雷希特专栏:艺术歌曲之王
2007年的一个上午,我敲响了柏林一座别墅的大门,工作人员带我进去,走进一间满眼深棕色的音乐室。迪特里希菲舍尔-迪斯考展示出的情绪也是一样的。这位伟大的艺术歌曲大师已步入了阴郁的衰老时期。在我们的谈话中,他回顾过往时带着遗憾,而非满足。“我的成就太多,”他抱怨道…

HPV防控迈入“男女共防HPV相关癌症及疾病” 的免疫预防新时代
2025年4月,佳达修9 [九价人乳头瘤病毒疫苗(酿酒酵母)](下文称“进口九价HPV疫苗”)多项新适应证获得国家药品监督管理局的上市批准,适用于16-26岁男性接种。这一获批使佳达修9成为中国境内首个且目前唯一获批、可适用于男性及女性接种的九价HPV疫苗,标志着中国正式进入了…

印度一航班因收到炸弹威胁紧急降落
资料图据总台记者消息,当地时间6月17日,印度靛蓝航空一架从喀拉拉邦科钦飞往首都新德里的航班,因收到炸弹威胁在马哈拉施特拉邦那格浦尔紧急降落。责任编辑:伍智超图片编辑:施佳慧澎湃新闻报料:021-962866澎湃新闻,未经授权不得转载

暴雨红色预警!广东珠海、中山、新会等地停课
受加强的西南季风影响,昨夜至今晨广东省南部沿海普降暴雨到大暴雨,局部特大暴雨。从广东雷达实况看,目前广东省的雷雨范围广,部分地区雨势强烈、电闪雷鸣,多地发布暴雨预警。在16日白天,湛江、茂名、阳江、粤北、珠三角北部、粤东市县出现大到暴雨局部大暴雨。据气象水文…

“苏超梗王”常州官方发文:与其被梗“淹没”,不如与民同乐
“‘苏超’话题共一石,常州独占八斗”——“苏超”以“地域梗”开路轰出流量,太湖之滨的经济强市常州队因积分垫底而饱受戏谑,喜提联赛“梗王”。6月17日,“常州发布”推送“输赢之外再看‘常州梗’”,首次作出正面回应:与其被梗“淹没”,不如与民同乐,城市的胸襟与自信…

2025伦敦科技周落幕 奔流城市对话圆满举行
日前,为期5天的2025年伦敦科技周在伦敦奥林匹亚会展中心落下帷幕。本届科技周以“AI时代的科技”(Tech in the Age of AI)为主题,议题覆盖生成式人工智能、量子计算、数字基础设施和监管等领域。今年的科技周有650多名演讲者、数百场会议,包括180位CEO、227位初创公司创始…

马上评丨小学生也能被“严重警告”处分吗?
近日,浙江瑞安市阳光小学公众号发布了关于两名小学生严重违纪行为实施惩戒的通告。通告中指出,两名小学高段的学生存在屡次辱骂教师、无故扰乱课堂秩序的行为,对其惩处以学期综合素质评定“品德表现”为D档,取消本学期评优评先资格;“严重警告”处分记入省学籍管理平台,并…
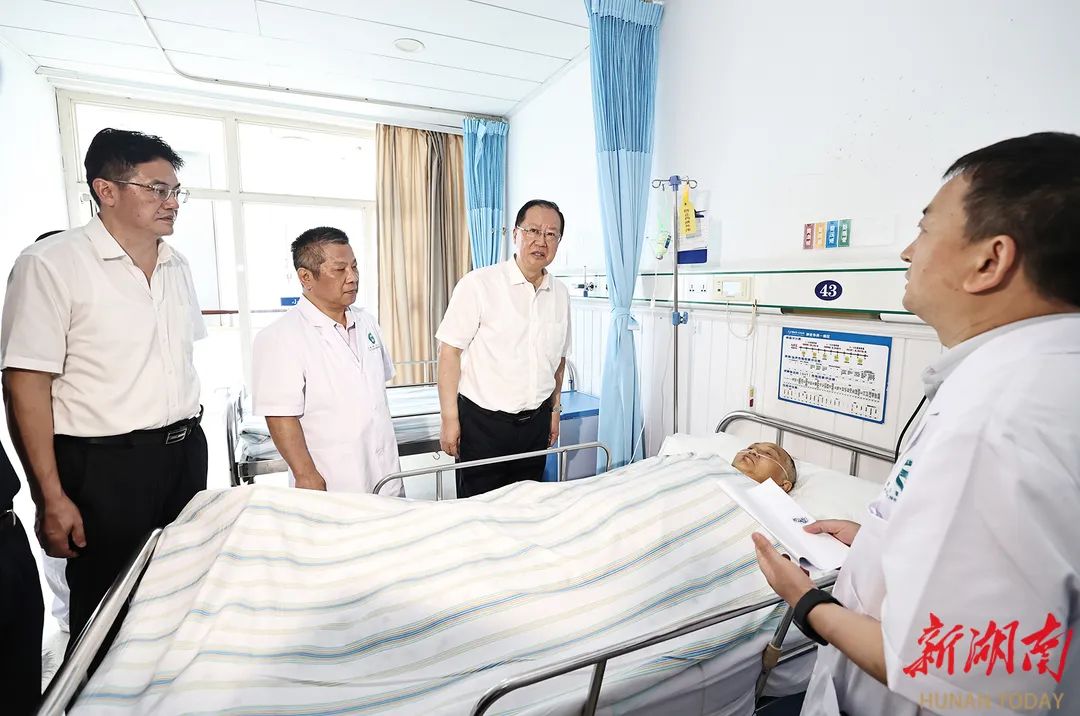
湖南省长赴常德临澧事故现场指挥救援并看望伤员
6月16日,湖南临澧县山洲烟花有限责任公司发生爆炸事故,造成多人伤亡。17日上午,湖南省委副书记、省长毛伟明赶赴事故现场指挥救援和善后工作,看望慰问受伤人员。他强调,要坚决贯彻习近平总书记关于安全生产的重要论述,扎实做好现场处置,全力以赴救治受伤人员,举一反三开…

波音787再出状况,日本一客机着陆后“抛锚”
日本大阪伊丹机场当地时间16日13时18分的监控摄像头画面据日本国土交通省大阪机场事务所消息,当地时间16日13时5分左右,日本全日空公司一架从北海道新千岁机场飞往大阪伊丹机场的客机(航班号NH774),着陆后出现在滑行道上无法移动的状况,导致机场部分跑道和滑行道一度临时…

浙商证券原总裁王青山起诉老东家,案由为劳动争议
浙商证券股份有限公司(简称“浙商证券”,601878)原总裁王青山因劳动争议与老东家对簿公堂。6月17日,浙江法院网资料显示,一宗原告为“王青山”、被告为浙商证券的案件,将于6月19日在杭州市上城区人民法院公开开庭,案由为劳动争议,案件排期日期为2025年3月6日。澎湃新闻…

上影节动画评委会主席《养家之人》导演托梅谈AI“入侵"
今年,上海国际电影节请到爱尔兰卡通沙龙动画工作室的奠基者之一诺拉托梅(Nora Twomey)担任动画单元评委会主席,她将与日本导演山村浩二、中国导演赵霁一同决定该单元奖项的归属。诺拉托梅担任金爵奖动画单元评委会主席《凯尔经的秘密》《海洋之歌》《养家之人》《狼行者》,…

“黄牛”围猎大学生国补名额:以佣金为诱,代购后转卖牟利
用自己的国补名额帮他们代购数码产品,每台能赚50元至100元的佣金。近日,有在校大学生向澎湃新闻反映称,有“黄牛”以代购赚钱为诱饵主动拉大学生入群“代购”,实际上是利用大学生的国家补贴名额,为“黄牛”购买手机、电脑、游戏机等国家消费补贴产品,并转卖牟利。澎湃新闻…

80岁阿婆为何坚守福州路电话亭?这个上海故事被搬上舞台
曾几何时,上海大大小小弄堂口的公用电话亭,是市民们最依赖的通信方式。从1952年上海有了第一部传呼电话开始,将近四五十年间,公用传呼电话亭一直是上海的城市风景。直到家用电话和手机普及,这些电话亭才纷纷关闭。沈玉琇阿姨(右二)和她的公用传呼电话亭但很多人不知道,…

陆川谈《借命而生》:每个镜头我都是用电影的方式拍摄的
看见芸芸众生顽强的生命力,也看到人性的挣扎与痛苦,改编自作家石一枫同名小说的影视剧《借命而生》以克制的镜头语言呈现社会转型期的冤案。近日,《借命而生》的研讨会举办。陆川导演形容,拍摄《借命而生》的那个山里很有“迷雾剧场”的氛围,“那个山里常年都是迷雾,杜湘…

重温经典|听英达谈谈《我爱我家》
在中国情景喜剧的发展史上,首播于1993年的《我爱我家》是一部“里程碑式”的作品。作为国内首部情景喜剧,该剧以20世纪90年代北京一个六口之家的日常生活为切入点,通过幽默诙谐的叙事,生动勾勒了社会转型期的众生相,成为反映改革开放浪潮中市井百态的一面镜子。剧中鲜活的…

易烊千玺雷佳音再续“长安宇宙”
“敢问道长名号?”“叫我长源即可。”在雷佳音主演的《长安的荔枝》第22集中,易烊千玺客串束发玉冠的道长长源,在李善德试验荔枝转运的过程中救下了他,并语重心长地劝他远离长安这个是非之地。《长安的荔枝》剧照在2019年播出,曹盾执导的《长安十二时辰》中,长安城陷入危…