直击谷歌I/O 2025:谷歌AI眼镜剑指主流市场,未来拍电影全靠“打字”?

AI能生成分镜,“拍”电影还会远吗?
北京时间5月21日凌晨,在2025年Google I/O开发者大会的主题演讲中,谷歌CEO桑达尔·皮查伊以一句轻松的“双子座季节”开场白,揭开了这场科技盛宴的序幕。他直言,在谷歌的“Gemini时代”,技术突破不再受传统发布周期束缚,谷歌正以史无前例的速度将最前沿的AI模型推向全球用户。

皮查伊强调:“我们打破了‘性能与价格不可兼得’的行业魔咒。”Gemini 2.5 Pro在性能飙升的同时,实现了成本的大幅优化。数据显示,Gemini模型每秒生成输出令牌数已跻身全球前三,而单位计算成本较前代下降40%。这一突破得益于谷歌第七代TPU芯片的赋能——这款专为大规模推理设计的芯片,性能较前代提升10倍,单计算仓算力达42.5 ExaFLOPS,成为支撑谷歌AI基础设施的“超级引擎”。
技术突破正转化为触手可及的产品体验。皮查伊公布了一组数据:过去一年间,谷歌每月通过产品和API处理的AI Token数量从9.7万亿激增至480万亿,增幅超50倍;开发者生态同样迎来爆发式增长,超过700万开发者通过Gemini API、Google AI Studio和Vertex AI平台构建应用,较去年增长5倍。其中,Vertex AI平台上的Gemini使用量更是飙升40倍。
在用户端,Gemini应用的月活用户已突破4亿,Gemini 2.5 Pro版本的使用量较前代增长45%。搜索领域的革新尤为显著:AI概览功能每月覆盖15亿用户,成为全球规模最大的生成式AI应用场景。皮查伊透露,谷歌搜索的“下一站”将是AI驱动的交互模式升级,用户将体验到更自然、更个性化的信息获取方式。
不仅如此,Google正通过三个研究项目,将实验转化为产品:

Project Starlight进化:Google Beam开启3D通讯时代历经数年研发,Project Starlight的3D视频技术正式落地为全新平台Google Beam。该平台通过6摄像头阵列捕捉用户动作,结合AI生成3D光场显示,实现毫米级头部追踪和60帧实时渲染。皮查伊现场演示了与惠普合作设备的沉浸式通话效果,并宣布首批测试设备将于年内推出。
Project Astra:跨语言对话的“无感翻译”作为实时语音翻译技术的集大成者,Google Meet现已支持英语与西班牙语的即时互译,未来几周将扩展至更多语种。演示中,系统精准还原了演讲者的语气、节奏甚至表情
Project Marina:智能代理的“操作系统”定位为“网络交互智能体”的Project Marina,已具备多任务处理和教学-重复学习能力。皮查伊展示了其如何同时管理10项任务,并通过一次演示学习完成复杂操作。该技术将通过Gemini API开放给开发者,首批合作伙伴包括Automation Anywhere和UiPath,预计夏季面向更广泛用户推出。
智能体生态:从工具到伙伴的进化

皮查伊将智能体(Agent)视为AI技术的“下一形态”。他现场演示了Gemini应用中的“代理模式”:用户只需设定需求系统即可自动调用Project Marina完成房源筛选、预约看房等操作,用户全程无需介入。这一功能将率先向订阅用户开放。
更深远的意义在于谷歌推动的“智能体互联计划”:通过开放的Agent-to-Agent协议和Model Context Protocol,不同智能体可共享数据与工具,构建协作生态。皮查伊强调:“这不仅是技术升级,更是对‘人机协作’模式的重新定义。”
Gemini 2.5:AI能力系统性跃升,开启多模态智能纪元
Gemini 2.5 Pro经过近期优化,在自然语言理解、代码生成、复杂推理及多模态处理(图像/视频)等领域全面突破性能边界,成为行业标杆。而轻量化模型Gemini 2.5 Flash则以22%的推理速度提升和更低资源消耗,提供与Pro相近的能力,计划6月率先开放开发者接入,重塑效率与成本的平衡。

本次升级的最大亮点在于原生多模态能力落地:
语音交互革新:全新文本转语音(TTS)技术支持24种语言无缝切换,可精准模拟人类语音中的情绪细节(如语速、语调变化),实现“情感化语音角色”生成。
视觉到3D的极速转化:用户仅需上传草图并输入提示词,系统即可在数十秒内自动解析图像、生成可交互的3D模型并部署上线,全程无需专业3D开发知识。
此外,谷歌推出AI编程代理“Rose”,支持从代码生成、错误修复到版本迁移的全流程自动化,标志着AI从辅助工具进化为“异步执行开发者”。现场演示的文本生成视频技术结合新一代低延迟架构,生成效率较前代提升5倍,预示生成式AI在视频创作领域的爆发潜力。
强化“深度思考”,加速构建“世界模型”生态
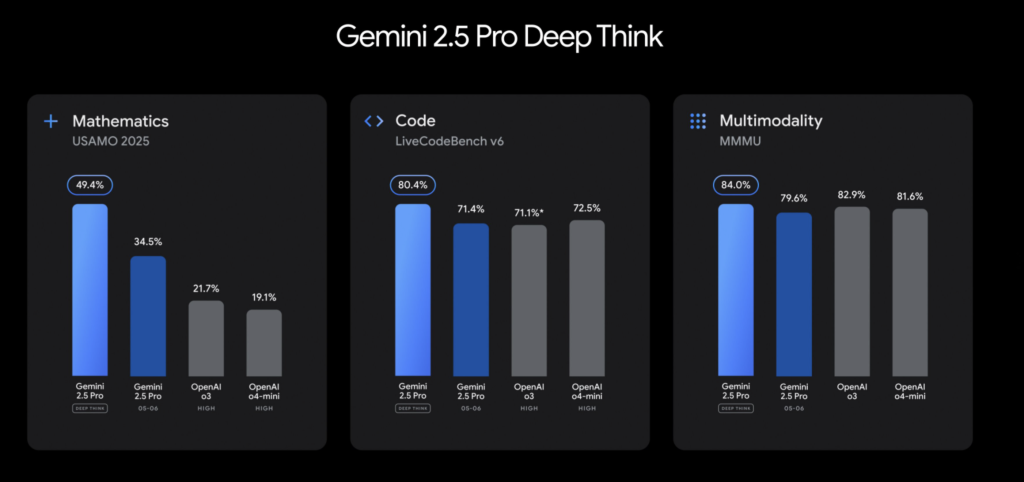
谷歌表示,Gemini 2.5 Pro的核心突破之一,就是引入了“深度思考”(Deep Think)能力,标志着AI向通用智能迈出关键一步。

Gemini 2.5 Pro通过集成谷歌最新推理架构,实现复杂任务下的“延时思考”能力。参考AlphaGo的策略性决策逻辑,该模型在分配更多计算资源时,可输出更具逻辑纵深的分析结果。
作为原生多模态架构,Gemini 2.5 Pro可跨文本、图像、音视频进行联合推理。更关键的是,谷歌正基于此构建“世界模型”——一个能实时映射物理规则、预测环境变化的虚拟智能体。现场演示中,Gemini仅凭简单草图生成可交互3D场景,并通过Gemini Robotics子模型驱动机械臂完成动态抓取任务,展现AI从认知到行动的闭环能力。

视频理解模型Veo实现了更多物理世界层面的理解:能精准模拟物体运动轨迹、材质反光特性及重力影响,甚至预测多物体碰撞结果。这一能力将赋能机器人、XR设备及物联网终端,使AI具备“预演现实”的规划力。

谷歌现场展示了“Gemini Life”场景:用户维修自行车时,AI可同步调取说明书、分析故障视频、搜索教学资料、联系配件供应商,甚至通过语音交互协调维修流程。这种跨模态、主动式服务模式,预示着AI将从被动工具进化为能自主规划、串联任务的“数字伙伴”,重新定义人机协作边界。
从信息索引到智能助手,Google搜索在AI模式下走向“质变”
Google强调,AI模式并非独立产品,而是搜索体系的进化试验场。其终极目标是将搜索引擎从“信息检索工具”升级为“思考伙伴”——用户不再被动接收链接,而是与具备判断力、执行力的智能体协同决策。当搜索能自主拆解问题、整合跨平台数据、预判用户需求时,一场关于人机协作的范式革命已悄然到来。
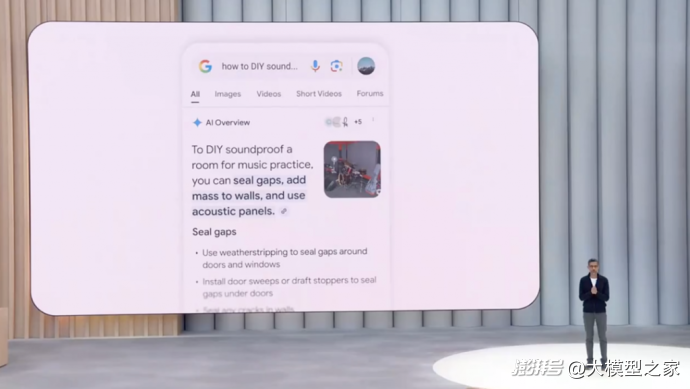
面对用户查询方式从关键词向复杂语境的转变,Google推出基于Gemini 2.5重构的“AI模式”,以多模态推理与全球信息整合能力重塑搜索体验。
技术层面,AI模式通过Query Decomposition技术实现“查询拆解”:系统自动识别需深度推理的问题,拆分为数百个子任务,调用定制化Gemini模型执行海量搜索,最终生成结构化报告——融合网页、知识图谱、地图等数据,附带来源验证、对比图表及可视化分析。例如,用户可一键获取球员使用新型球棒后的击球率趋势图,或跨平台比对红袜队比赛门票价格并完成订票流程。

个性化则是另一大亮点。Google即将推出“个人情境”功能,搜索结果可以结合Gmail中的行程信息、用户的偏好数据等做出更贴合生活的推荐。例如,当用户搜索周末活动建议时,系统会知道其刚刚订了户外餐厅,或订阅了某个画廊的信息展,并提供匹配推荐。同时,用户对自己的信息接入权限具有完全控制权。

除了文本和数据的处理能力,AI模式还全面升级了视觉搜索体验。Google Lens的月活跃用户已超15亿,而AI模式引入了Project Astra的实时视觉交互功能——“实时搜索”。用户可以通过镜头直接展示问题场景,如DIY项目、科学实验或复杂设备操作,搜索引擎则仿佛“视频通话中的助手”,在实时画面中给出精准指引。通过AI眼镜的多模态互动,正成为“下一代搜索”的关键入口。
图像与视频生成的质变:Imagen 4与Veo 3齐发
在生成式内容方面,Google带来了新一代图像模型Imagen 4和视频模型Veo 3。Imagen 4强化了图文混排、细节表现和构图逻辑,能够根据简单的描述生成用于音乐节、品牌活动等场景的高质量海报。而Veo 3则实现了视频生成的一个质变——首次引入“原声音频生成”(Native Audio Generation),不仅画面栩栩如生,背景音效与角色对话也可一并生成,实现真正意义上的沉浸式内容生产。

Veo 3所展现的能力,标志着生成式AI正在重塑影视制作的整个流程。Google透露,已与电影制作行业展开深入合作,探索AI生成内容的专业化路径。
谷歌还首次揭示了Gemini Agent模式下的多模态操作方式。这是一个可在Chrome中工作、支持多任务协作的AI代理,能够实时理解网页语境、对比评论、自动整理信息,为用户提供上下文感知的帮助。
会上,谷歌还发布了Lyria,这是一款能够生成高保真、专业级音频的新模型。无论是独唱还是合唱,其生成的音乐在细节和情感表达上都展现出强烈的感染力。
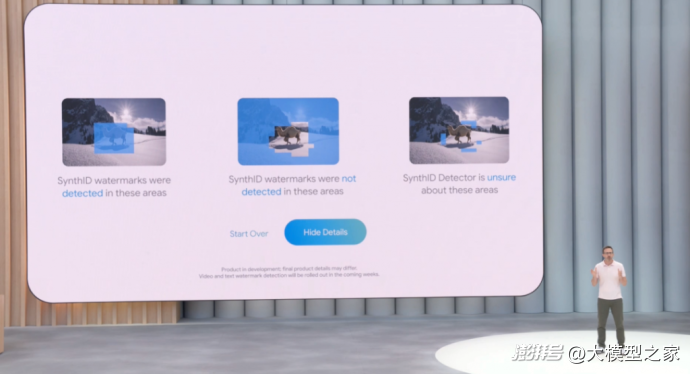
在生成内容日益逼真的背景下,谷歌延续其在媒体透明化上的探索。早在两年前推出的“SynthID”水印技术,如今已覆盖超过100亿条生成内容,并获得进一步升级。此次更新引入了多模态检测器,不仅能识别图像是否含有隐形水印,也可以判断音频、文本及视频是否部分或完全由AI生成。
这一技术的扩展不仅是技术性的进步,更是回应社会对于AI内容来源可追溯性的迫切需求。谷歌强调,他们正扩大与全球合作伙伴的协作,以将此类可识别机制推广到更广泛的生成式媒体生态中。
颠覆创意生成范式,AI视频创作新引擎 Flow
作为活动的一大亮点,谷歌发布了一款专为创意人士打造的AI视频制作工具——Flow。这款工具集成了Veo、Imagen和Gemini,是一个从灵感萌芽到成片输出的完整内容生产引擎,意在重塑创意素材的生成方式。
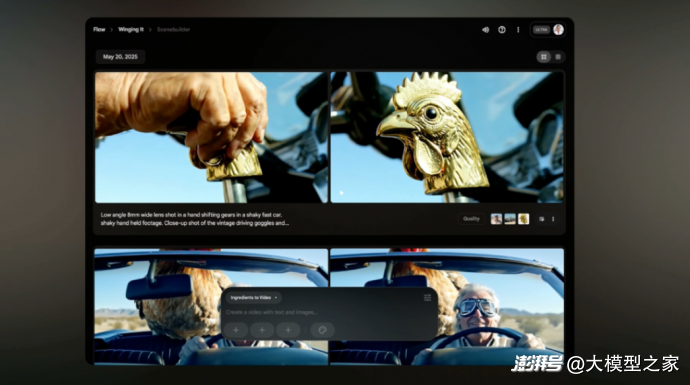
Flow不仅仅是一个视频工具,它是一个能与创作者的构思实时互动的AI伙伴。通过自然语言输入,创作者可以设定人物、场景、情节,甚至详细到镜头调度和画面风格。谷歌在现场演示了一个案例:一位祖父希望制造一辆“能飞的小汽车”送给孙子。创作者只需描述角色和剧情设定,Flow便可即时生成画面素材;再通过轻松的拖放和编辑,逐步将片段串联为完整短片。
创作过程中,用户不仅可以添加镜头,更能定义每一个镜头的情绪、节奏与画面风格。Flow具备保持风格一致性的能力,使得即便是由多个生成模块构建的作品也具有统一的美术表现力。更重要的是,所有素材都可以被导出至主流视频剪辑软件,创作者仍然拥有对最终成品的完全掌控。
谷歌强调,Flow不是在取代导演与编剧的角色,而是在构建一种新的创作流程:灵感涌现时,AI可以立即响应;创作陷入瓶颈时,AI可以提供提示和延展。从某种意义上,它帮助创作者“看见”那些尚未成形的想法。
在AI的辅助下,故事结构在眼前展开,角色仿佛拥有了自己的生命。创作者从“努力去做”,逐渐转变为“纯粹地表达”,这也许正是生成式AI对创意产业最深远的改变。
Gemini进入XR设备,智能眼镜走向量产
继Android 16与WearOS 6的发布后,谷歌正式将AI助手Gemini嵌入到更广泛的设备形态,从手机走向手表、汽车仪表盘、电视,再一步扩展到全新的XR平台。

为了应对用户在不同场景下的使用需求,谷歌发布了XR领域首个Android平台——Android XR。这一平台支持从沉浸式头显到轻巧便携的智能眼镜,打破了传统单一设备的限制。谷歌明确指出,XR不是一个通用方案,而是一个多形态协同生态。在处理工作或娱乐时,用户可以佩戴高性能头显;而在移动场景中,轻便的眼镜则成为理想助手。
这一战略正在由谷歌与三星、高通联合推进。首款搭载Android XR的设备是三星的Project Moohan头戴装置,通过Google Maps XR功能与Gemini整合,用户只需发出语音指令,便能沉浸式“瞬移”到全球任意地点。在体育应用中,例如MLB,用户可以仿佛置身球场,实时获取球员数据和赛事分析。

谷歌在现场演示中首次揭示了新款搭载Android XR的智能眼镜——这款设备历经十年探索而成,强调全天佩戴的舒适性与技术集成能力。它内置摄像头、麦克风、扬声器和可选的私密显示镜片,支持全语音交互,不需掏出手机即可完成导航、搜索、通信等操作。
通过与Gemini联动,这款眼镜具备“所见即搜索”的能力。用户看见一个咖啡杯上的Logo,即可让Gemini识别品牌、显示地图、预约时间,甚至播放相关音乐。这一切,都无需动手操作。现场还展示了实时翻译功能,不同语言的对话被同时翻译为英文浮现在镜片中,打破语言壁垒。
目前,首批智能眼镜产品已进入可信测试阶段,并将在近期开放开发者平台。谷歌还宣布将与时尚眼镜品牌Gentle Monster和Wabby Parker合作,打造首批基于Android XR的消费级智能眼镜,通过可日常佩戴的时尚配件,打入主流市场。
AI普惠时代的“谷歌答案”:下一步的AI,不再抽象
“十年前,我们谈论AI的可能性;今天,我们正在见证其从理论到实践的转化”。可以见得,谷歌正通过整合基础模型研发、三维交互技术、智能代理系统及个性化服务等领域能力,构建全栈AI技术架构。
不难预见,随着其生态系统向硬件终端的持续渗透,人工智能与物理世界的深度融合进程已呈现明确的发展轨迹,将为产业价值的提升带来更多确定性。
本文为澎湃号作者或机构在上传并发布,仅代表该作者或机构观点,不代表的观点或立场,仅提供信息发布平台。申请澎湃号请用电脑访问http://renzheng.thepaper.cn。
相关文章

科学与艺术的跨界对话可能吗?——评“以蚁为序的生命网络”

“共栖与绵延”系列对话|张国捷、刘帅:以蚁为序的生命网络

福建省委副秘书长、政研室主任郭国云已赴厦门履新

日本农林水产大臣因不当“大米言论”引咎辞职

马上评|当众猥亵女演员,没有任何开脱理由
引入AI Mode聊天机器人,Gemini 2.5 Pro加持,谷歌重塑搜索智能
1309家县医院已达到三级医院能力,还有哪些短板要补?

2025年上海市工程建设标准国际化工作要点发布

王晋卿读《酒的精神》︱乏味时代的有味之思

第九届非遗节将于五月下旬举办,600个非遗项目将参展参演

嘴巴总是发干,喝水也不管用?小心是这几种疾病的警报

六个最伤脊柱的姿势,你可能天天在做

从马相伯到谢希德:复旦大学校长传记系列再版首发


特朗普宣布打造“金穹”导弹防御系统,计划3年内运转


华生是养了狗,还是藏了枪——《福尔摩斯探案全集》翻译一例

单人飞行器首次实现海拔5000米载人试飞
