DeepSeek V3.1再更新:缓解中英文混杂,智能体输出更稳定
DeepSeek-V3.1已更新至DeepSeek-V3.1-Terminus版本。
9月22日晚间,据DeepSeek介绍,此次更新在保持模型原有能力的基础上,针对用户反馈的问题进行了改进,包括:语言一致性:缓解中英文混杂、偶发异常字符等情况。在Agent(智能体)能力方面,进一步优化Code Agent与Search Agent的表现,DeepSeek-V3.1-Terminus的输出效果相比前一版本更加稳定。
目前,官方App、网页端、小程序与DeepSeek API模型均已同步更新为DeepSeek-V3.1-Terminus。不过,记者看到这款大模型名为Terminus,意思是“终极版”,或许这也是V3.1最后一次更新。外界观望下一次大版本更新到底是V4还是R2的到来。
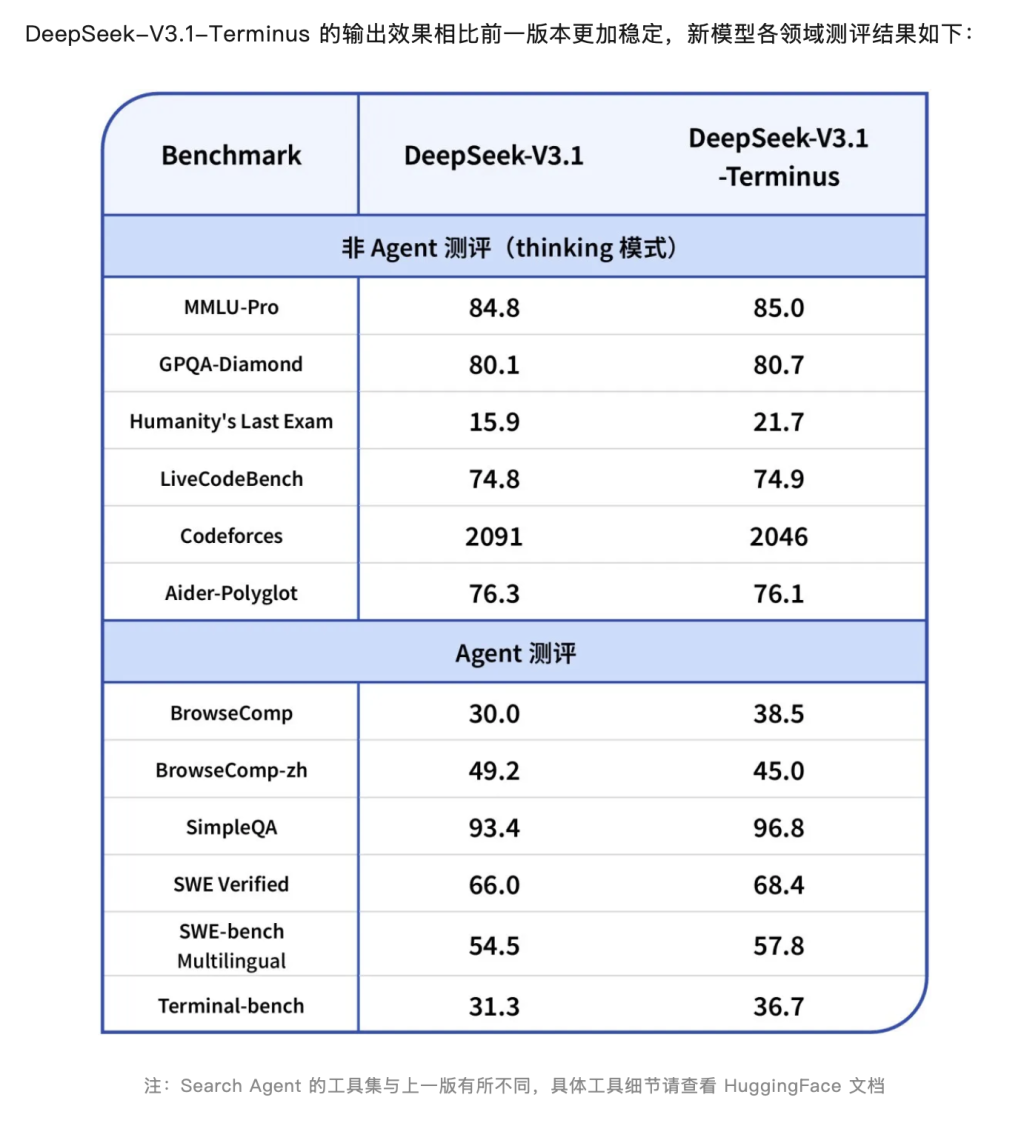
在公开的基准测试成绩中,V3.1-Terminus整体较V3.1有所提升,不过其中部分分数也有下滑,不过在“人类最后考试”(Humanity’s Last Exam)基准上进步较为突出,分数从 15.9大幅提升至21.7,根据官网数据,这一成绩仅次于 Grok 4(25.4)和GPT-5(25.3),并略微超越 Gemini 2.5 Pro(21.6)。
值得注意的是,DeepSeek在中英文混杂方面的改进尤为受到欢迎。记者在社交媒体上看到,不少用户点赞:“中英文混杂问题在思考时间很长的时候确实会出现,遇到过几次,还在想这是什么问题,这下子正好给解决了。”
资深AI投资人郭涛向记者分析称,本次DeepSeek-V3.1-Terminus版本更新聚焦工程化落地与场景适配,核心突破体现在两大核心竞争提升:一方面,通过语义层降噪技术显著改善语言一致性,有效抑制中英文混杂、异常字符等干扰,提升文本生成纯净度;另一方面,深度重构Agent执行框架,针对Code Agent的语法解析精度、Search Agent的信息检索召回率进行专项优化,使智能体输出稳定性提升。
此次全渠道(App/网页/小程序/API)同步升级,展现国产大模型从算法创新向工程可靠性演进的关键跨越,标志着国产模型在复杂任务处理、多模态协同等工业化应用层面迈出重要一步,为后续垂直领域深度赋能奠定更坚实基础。
作为国产大模型的风向标,DeepSeek的动态都广泛被外界关注。
此前9月18日,梁文锋带着DeepSeek-R1的研究,登上最新一期国际顶级期刊《自然》(Nature)封面。
今年1月份,国产大模型公司深度求索(DeepSeek)在预印本平台arxiv公布论文《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》,创始人梁文锋位于署名之列。
《自然》杂志指出,如此总结DeepSeek-R1带来的进步:如果训练出的大模型能够规划解决问题所需的步骤,那么它们往往能够更好地解决问题。这种“推理”与人类处理更复杂问题的方式类似,但这对人工智能有极大挑战,需要人工干预来添加标签和注释。
DeepSeek的研究人员揭示了他们如何能够在极少的人工输入下训练一个模型,并使其进行推理。DeepSeek-R1模型采用强化学习进行训练。在这种学习中,模型正确解答数学问题时会获得高分奖励,答错则会受到惩罚。
DeepSeek团队也首次对外回应“蒸馏”相关质疑。论文中表示,对于深度求索V3基础版(DeepSeek-V3-Base)的训练数据仅使用普通网页和电子书,未纳入任何合成数据,“不过,我们注意到部分网页包含大量由OpenAI模型生成的答案,这可能会让基础模型间接地从其他强大模型获取知识。但在预训练冷却阶段,我们并未刻意加入由OpenAI生成的合成数据;该阶段使用的所有数据都是通过网络爬取自然获取的。预训练数据集包含大量与数学和代码相关的内容,这表明深度求索V3基础版接触到大量的推理轨迹数据。”
今年1月20日,中国AI初创公司深度求索(DeepSeek)推出大模型DeepSeek-R1引爆AI行业,作为一款开源模型,R1在数学、代码、自然语言推理等任务上的性能能够比肩OpenAIo1模型正式版,并采用MIT许可协议,支持免费商用、任意修改和衍生开发等。春节假期后,国内多个行业龙头公司均宣布接入DeepSeek。
伴随AI大模型行业的日新月异,DeepSeek已经更新出R1以外的新版本,但万众期待的R2尚未面世。此前8月21日DeepSeek正式发布DeepSeek-V3.1,称其为“迈向Agent(智能体)时代的第一步”。
相关文章

上海迪士尼“飞越地平线”承载量将扩建约50%,扩建期间持续开放
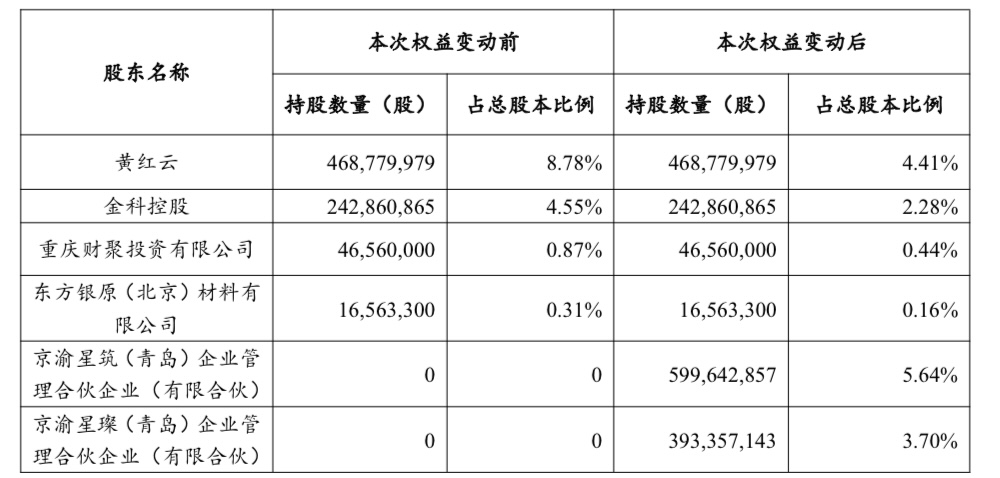
金科地产:控股股东拟变更为京渝星筑和京渝星璨,公司无实控人,将启动董事会改选
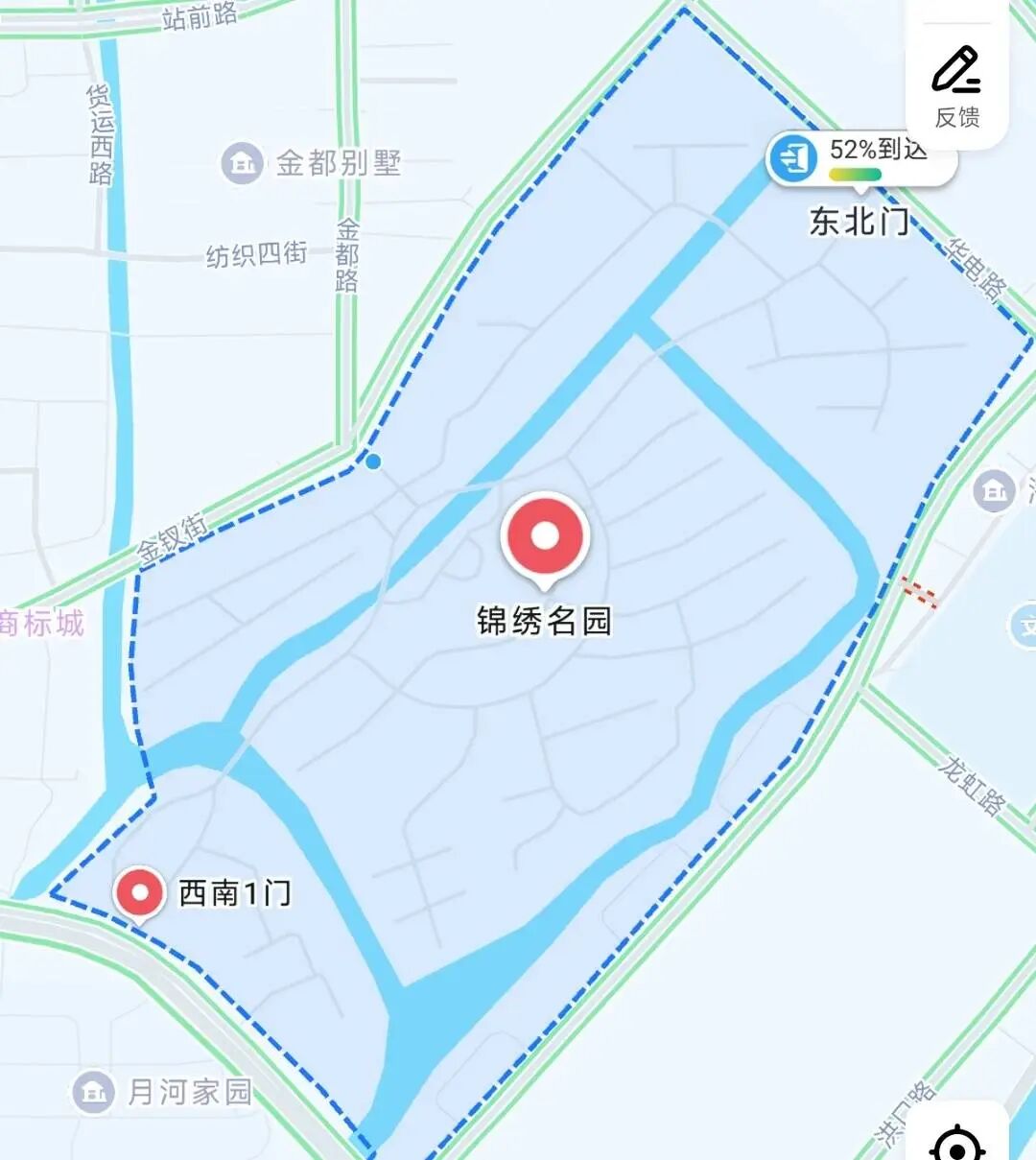
业主私挖地下室导致河道被挖通,地下车库被淹?温州龙港回应:正在勘验调查
业主私挖地下室导致河道被挖通,地下车库被淹


同济大学生命科学与技术学院副院长张敬逝世,年仅57岁
当爱优腾开始比拼“长尾效应”
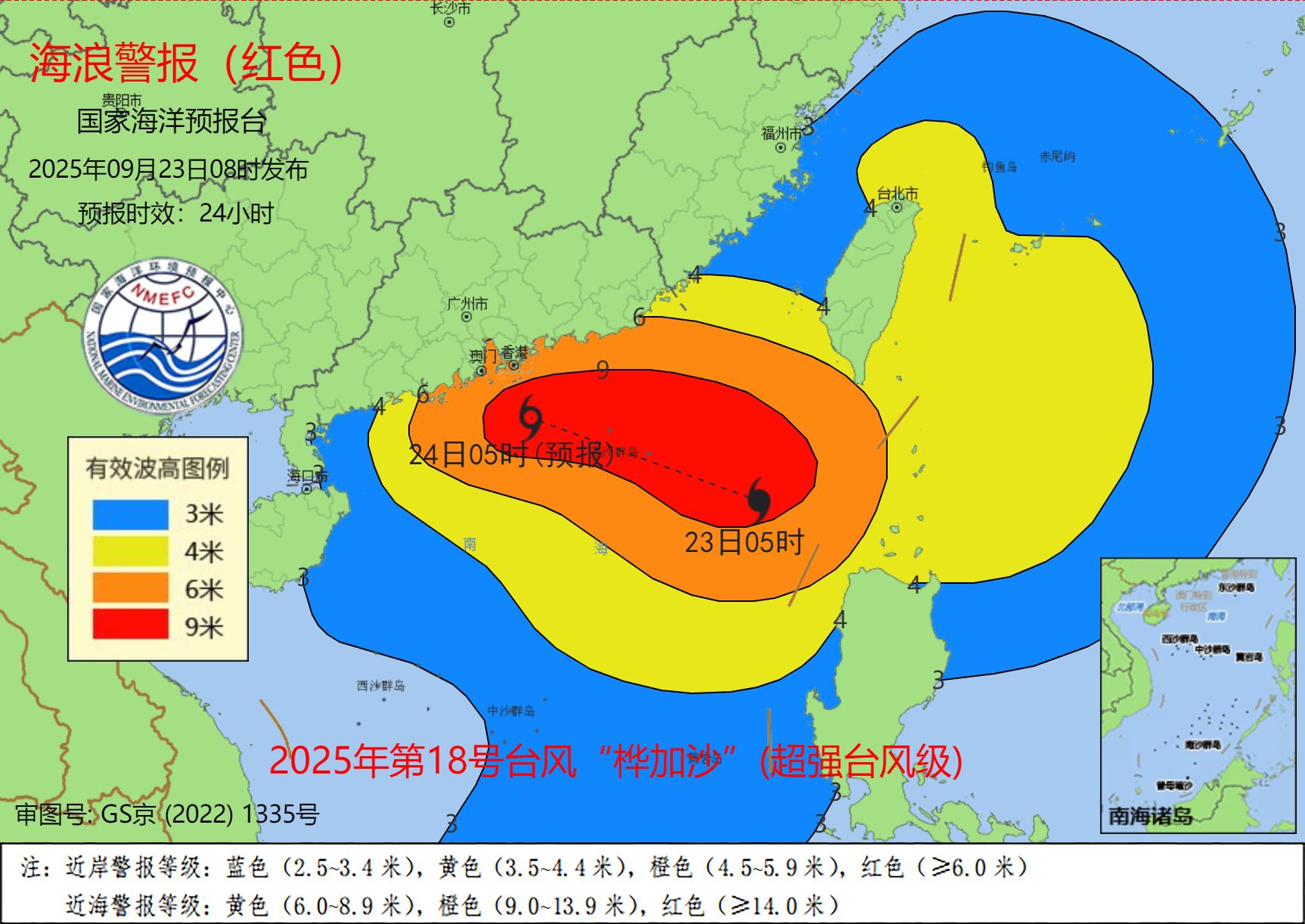
国家海洋预报台发布风暴潮红色警报和海浪红色警报

人流量之外,上海光影节为夜经济还带来什么?

广州、深圳回应台风前蔬菜被“抢空”:储备充足,“别担心!菜管够!”
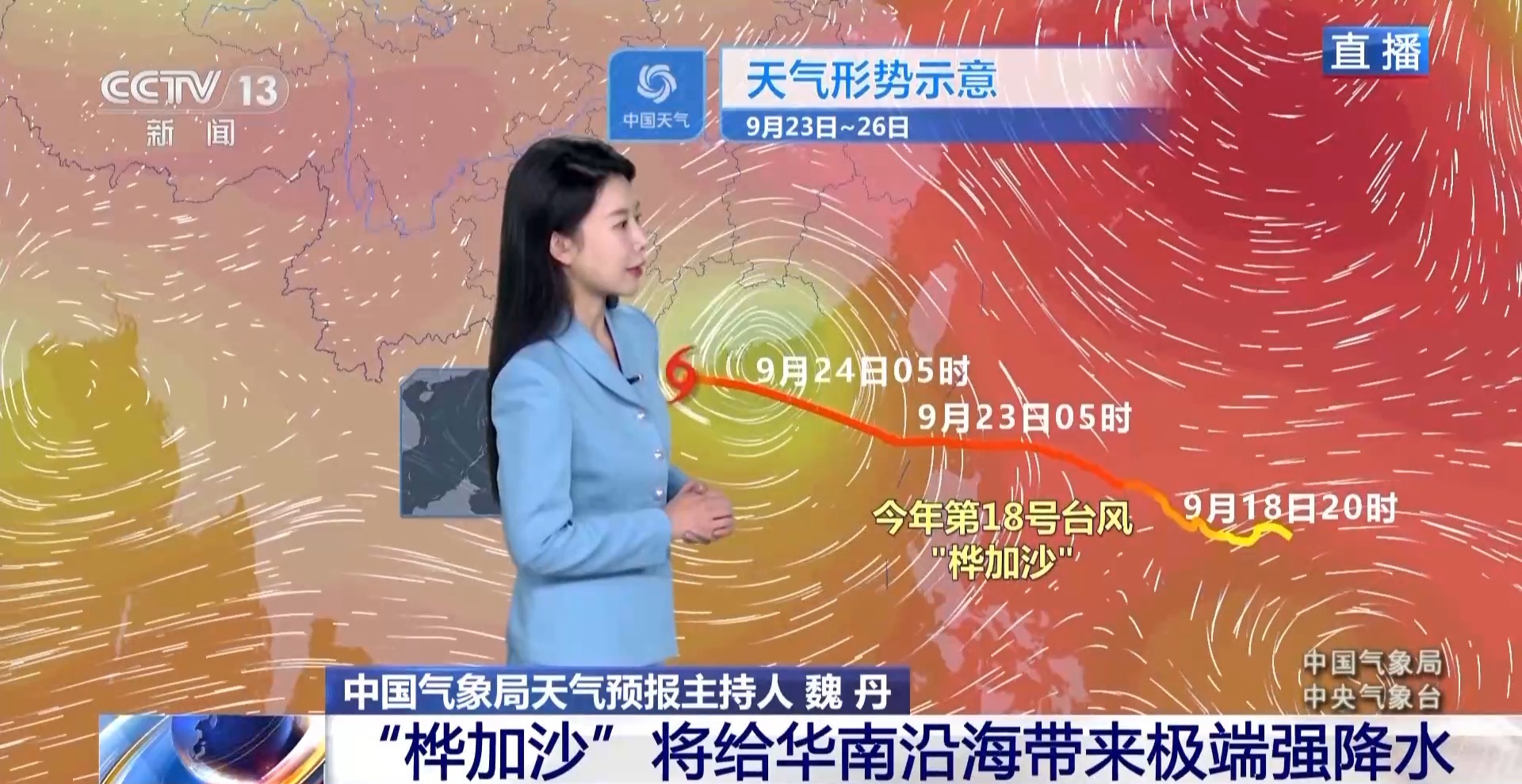
超强台风桦加沙预计24日登陆广东沿海,气象部门提醒防海水倒灌

南昌风洞原址广场项目拟于国庆前对外开放,将与八一广场等景点串联起来

秋分时节,煨一碗鲜菱

二十四节气与民间艺术|一刀一刻里的秋分诗韵


特朗普称自闭症与泰诺有关联,美专家指责其“不负责任”

张文宏:通过优化治疗方案,结核病短程治疗费用可降低90%以上

美国对参加联合国大会的伊朗代表团实施出行限制

特朗普签署命令,将美国左翼激进势力“反法西斯主义运动”列为恐怖组织

银川一国家级城市湿地公园被指“水泥封树坑”,当地自然资源局回应
- 消博会参展外企坚定看好中国市场:对中国经济基本面和强大韧性充满信心
- 共享单车、公共设施表面等频现“小广告”?上海将出手治理
- 携手81个国家和区域一体化组织,中国加入这个共同维护国际渔业秩序的协定
- COP30候任主席答澎湃:走自己的务实道路,不依赖发达国家“标准答案”
- 大外交|习近平时隔9年访柬,专家:中柬铁杆友谊的地区意义日渐凸显
- 巨能吃辣和一点辣都不能吃,哪种人的体质更牛?
- 德黑兰将实行夜间限水措施
- 美国参议院继续就政府“停摆”谈判
- 比利时列日机场因发现无人机一度中断运营
- 美国纽约地区三大机场均因人手短缺出现航班延误
- 台湾各界秋祭白色恐怖死难者,呼吁携手推进统一大业
- 新闻调查丨广西百色排涝情况如何?记者探访受灾村屯