AI之用|盲者与天鹅——AI时代的咒语与图像之谜
前言
从在自然的平面上拓画,到在电脑屏幕上用AI生成无穷无尽的图像洪流。图像,通过我们的主体感受,塑造着我们的世界意识,也是我们与世界爱欲交流的重要频道。
只是,在今天这个“技术图像的宇宙”(弗鲁塞尔所言)中,不断增殖的图像,是否正在以前所未有的方式,不断形塑我们本已支离破碎的世界意识,修正岌岌可危的生存环境?更多的图像,究竟是让我们生活得更加丰饶,还是更加贫瘠?我们是否还能如同过去一样,通过镜子和影子——这些人类最早认识图像和自我的方式,确认自己在世界上的存在?
与此同时,在这一波以大语言模型为突破的AI图像的技术浪潮中,占据四千多年文化统治地位的线性文字首次成为图像的先声,而不是像自然经验那样,让图像先于文字进入我们的视野,心灵和头脑。直观的领会和无需解释的世界早已消散,语言的脚手架密密麻麻地爬满图像殿堂,遮蔽了我们原本应有的图像想象力。这种能力的丧失,最终意味着什么?
所以,在今天的环境里,以本体论的方式追问“AI绘画(生图)是什么?”“AI能否替代人类绘画?” 或者“AI绘画的艺术价值几何?”并非最为急迫的问题。本文试图从语言问题进入,来讨论从文生图的逻辑出发的图像。在第二部分,我们考察AI生图的技术链路与摄影术在生成方式和方法上的类似之处,进而探讨机械艺术和技术图像,如何令我们承担了更多丧失主体性的痛苦。最后,本文试图通过AI中的万物风格迁移,进入艺术史的舞台来重新认识AI图像这位“强力的入侵者”。
咒语
一个盲人和朋友在餐厅吃饭,朋友帮他点了一杯牛奶。他问朋友,牛奶是什么?朋友说,牛奶是一种白色的液体。盲人又问:白色是什么?朋友说,白色是一种颜色,就像天鹅的颜色一样。盲人继续问:那么,天鹅是什么?朋友说:天鹅是一种脖子弯曲的鸟儿。盲人还问:弯曲是什么?朋友生气了,抬起胳膊说:你摸摸我的胳膊,这就是弯曲。
于是,盲人仔细摸了摸朋友的胳膊,高兴地说:现在,我终于知道牛奶是什么了!
我们不妨从这个小故事来思考AI的“文生图”(text-image)功能。在这个故事里,AI被类比为一个不具备感官能力的盲人。因此,当盲人需要理解“白色”这种在经验世界无需解释、一目了然的事,却只能通过一连串以语言为媒介的比喻、象征和逻辑推导。盲人最终认识到,“白色”作为概念的存在可以和其他概念等价交换。但由于缺乏直观经验,他得出了一个荒谬的结论。
那么,现实生活中的AI是如何能够正确地“看”到世界的呢?
AI知名学者、斯坦福大学教授李飞飞在《我看见的世界》一书中写道:最初使用imageNet做计算机视觉训练的方法,是用一个有明确文字标签的广阔图像数据集(超过一千万张)训练机器,把图像(pixel data)数据输入神经网络,让标签(text category)作为监督信号,机器则开始学习图像中哪些特征对应哪些类别,从而建立图像“特征-类别”标签的数学映射关系。
从一开始,机器就和故事中的盲人一样,不具备感官能力,它没有真正地“看”见任何东西。对它的训练,主要集中在让它理解图像和语言的关系,以及让它能较好地完成文字图像对齐(text-image alignment),如此一来就能让它表现得像是“看”懂了图像。
而我们今天所使用的大部分AI图像创作模型,无论是Stable Diffusion, 还是Midjourney (下称MJ),Google Veo,chatgpt 4-o 等等,它们虽然都各自发展出了高度复杂、跨模态、深层的图像生成系统,但在方法论上,遵循的都是imageNet所奠定的语言-图像的基本逻辑。
所以,这也就不奇怪,为什么所有AI生图的基本前提,必须是一个文本输入框。这不是什么无中生有的神奇魔法,而恰恰是由于AI不具备真正意义上“看”的器官所致。我们都知道,一段关于画的说明文字,不等于这幅画。而AI却试图用栩栩如生的结果说服我们,这两者是一回事。
在要求MJ生成的上世纪80年代家庭相册中的照片中,我们能够看到,它选取了“家庭”“80年代”和“家庭相册”几个语义清晰的提示词进行图像合成,同时,类似GPT-4或其他Transformer架构模型,它们对更长的token输入有了更强的“上下文一致性”维持能力,会在某些高频语义搭配中“补全”一些未被指令明确要求的细节,比如,将翻拍胶片相片的反光,也自动涵括在数据映射集中,进行高度的拟合,给我们造成一种逼真的历史感。但这与我们希望它“理解”相片的历史环境,形成判断和印象,进一步明白相片中人物的关系和感情进行创作,却是完全不相干的两码事。

80年代家庭相册中的照片,由Midjourney生成
原本“纯粹落在语言之外的东西”,如今也必须要走语言所规定的道路——Prompt(提示词)成为所有想象力的起始和开端,它曾一度被翻译为“咒语”,这是一个非常有趣的译法。它无意中点出,机器模型对我们来说就是一只不透明的神谕盒,我们无需知晓其运作原理,只需对其膜拜祈咒,便可以得到想要的结果。文字从能指符号,变成了带有前现代巫术特征的东西;而图像,却在咒语的束缚下,丢失自己的想象、直观与混沌。
那么,咒语究竟要多精确,才能复现出我们头脑中的印象,我们的记忆,和我们所期待的图像呢?
为了验证这个问题,我用诺贝尔文学奖获得者埃尔诺的书籍《相片之用》做了一个AI再创作的实验。
埃尔诺的写作,本身就被称为“照相机风格”般的文本,特别是在特殊的、非常私人化的《相片之用》一书中,埃尔诺先是和她的情人布鲁诺,共同挑选了一些他们拍下的日常“快照”,然后在互不交流的情况下,分别对这些照片做出文字性的描述。这是两个人类,用文学意义上质量最高的文字,对一系列图像做出的极为细致的描述。作家用这个方法,构筑了一段关于癌症、爱情和生命历程的故事。
那么,AI能够再次通过这些文字,还原出他们曾经经历过的场景吗?我把埃尔诺如同图像咒语般的文字,原封不动地给了MJ。
埃尔诺的原文如下:
进门处由浅色大块地砖铺成的整条走廊上到处散落着衣服和鞋。前景处,右侧是件红色套衫——或衬衣——和一件黑色无袖短套衫,它们看上去像是在被扯掉的同时还翻了过去。好似一尊袒胸露肩、被砍去了双臂的半身像。无袖短套衫上的白色标签很显眼。更远处是蜷缩成团的蓝色牛仔裤,上面扣着条黑色皮带。牛仔裤左侧是红色外衣的红色内衬,像粗麻布拖把一样摊开着。上面放着一条带有蓝色格纹的男士短衬裤和一件白色文胸,文胸的肩带朝着牛仔裤伸去。后方是一只倒向一侧的男士长筒靴,旁边是一只缩成团的蓝色袜子。一双黑色的薄底浅口皮鞋立在那里,两只鞋彼此之间离得很远,鞋的朝向摆成个直角。更远处,套衫或裙子构成的一团黑色从暖气片下方露了出来。另一侧,沿着墙边的是一小团无法辨认的黑白色衣物。画面最深处可以看到一个衣帽架,还有衣架上挂着的风衣下摆。闪光灯照亮了整个场景,使地砖和暖气片显得愈加亮白,也使侧放着的那只皮鞋闪着光泽。在从一扇门的门框处拍摄的、同一场景的另一张照片上,我们可以看到另一只男鞋和另一只袜子,独自留在了楼梯的台阶前。
MJ 遵循提示词生成的照片:

以埃尔诺的文字为提示词,通过Midjourney生成的图片

埃尔诺书中拍下的照片
事实上,我和所有尝试用AI生图的人一样,一遍又一遍地调整Variety(多样性) 和 Weirdness(怪异度)(这两个都是MJ为了增加图像风格多样性和离散程度而设计的用户滑块),以期获得我满意的图片。但是,我们不难发现,无论如何调整参数,试图通过精确的文字获得精确的图像,是注定失败和不可能的。甚至,提示词越精确,得到的结果越糟糕。
AI图像无法逃脱咒语的限定,而AI目前处理“非秩序场景”的方法,要么总是显得模板化、安全和整齐(鞋子总是摆放得太整齐,成对出现,不会像真实生活那样随机),要么它就像一个不知道停手的疯狂画家,从像素画到像素,开始堆砌色块,图像出现轮廓丧失和颜色泥化(衣物失去了原本应有的结构和形状)等问题。它无法把“有组织的杂乱”表现得像真实世界那样可以理解——这不是通过调整参数就能解决的问题,而是目前扩散模型和token化机制的结构化限制。归根到底,AI生图的本领建立在统计学的基础上。从本质上来说,是机器在语义连贯性和空间秩序上,努力模仿人类直观地从生活经验中获得的印象。

阿米戈酒店223号房间(Midjourney生成的图片)
埃尔诺的文字不仅精确描写了物的形象,还在行文之间埋藏象征、比喻和尖锐的情感指向,这些都无法在AI生成的相片中得到准确的传达。
延伸开来说,在这个实验中,另一个和摄影伦理相关的问题是——机器生成的,是“应该存在而实际上不存在”的图像。但真实的相片,则永远指向一个具体的事件和情境,也就是罗兰·巴特(Roland Barthes)所说的“ça a été”(That has been) ——这曾经存在。埃尔诺写下的文字,对应着他们曾经共同经历过,在癌症中拥抱生命,激情地活着的历程。相片,就如同法庭上的呈堂证供,提供着一种不容辩驳的、曾经在场的真实性。

阿米戈酒店223号房间(照片)
让我们再次回到那个问题:无论AI如何说服我们,一张关于图片的说明,就等于这张图片,这都是不成立和不可能的。
当然,一定会有人提出,除了text-img选项,大部分AI生图模型,不是都几乎同一时间,贴心地提供了图生图(image-to-image)的选项吗?那么,我们能够把它看作是摆脱语言牢笼的AI创作吗?我们能够认为,语义引导的结构在这里不存在吗?事实并非如此,这个工作流中的前一个图像,只能被看作另一组图像形式的提示词,而后一个图像,则是基于已有图像的潜在( latent) 结构进行再建模或修正的结果。
图生图是对文生图模式的补充,甚至我们还可以把它增加至声音+文字+图像的更多模态引用,它似乎把我们缓慢地拖离语言中心主义,但就其形态和目的而言,它依然是从像素到像素的存在。在这里,没有真正的世界存身的空间。
那么,人类艺术家们,源于文本和现成的图像的创作又是如何的呢?米开朗基罗的西斯廷天顶绘画——7幅表现圣经旧约内容的故事绘画,被高高悬挂在天穹之上,从创世纪到大洪水,从上帝制造亚当到夏娃和蛇,每一幅都对应着人们耳熟能详的故事文本。不仅仅是米开朗基罗,在贯穿西方艺术史大量的宗教题材绘画中,假如我们把圣经文本当作一个先决的提示词(prompt)集合,那么,它是否就为文生图提供了海量的图像实例?
米开朗基罗不是第一个画圣经的艺术家,显然也不是最后一个,他生活在人类前后相继的视觉传统中,对历史有直接观看以及触摸的经验。他未必是从圣经的语言出发来机械地图解化这些故事,而是直接面对大量的图像集合和艺术实例。虽然上帝这一概念是形而上的,但其形象却是历史中的人通过总结、沉思、搏斗和再象征得到的。米开朗基罗通过观看、触摸、体会、感受人类实体,做出了自己的图像回应,重建了视觉历史的秩序。
其次,圣经是文学的语言,是神话和寓言的世界,而不是提示词式机械地执行指令,人类之所以理解圣经所阐述的故事,是因为我们就生活在世界之中,我们借助故事来阐发自己对生存的渴望、激情和感受。而对AI来说,世界的存亡与否都无关紧要,它只需要执行数据点,计算特征向量,按照统计概率输出结果即可。
事实上,上帝创造亚当的时候,他是怎么说的呢?
“要照着我们的形象、样式造人。”(“Then God said, ‘Let us make mankind in our image, in our likeness…and let them have dominion…’ So God created mankind in his own image, in the image of God he created them; male and female he created them.”) 在这里,上帝并没有先写下一段造人的提示词,他直接从自己的形象里,造出了人。
图像一词,除了外显之形、显现、影像的意思,还和想象(imagination)共享了同一个拉丁文原文imago, 它还意味着,在心中再造“形象”的能力,因此,图像不仅是人的被造状态,更是人的想象性本质。而如今,线性的文本预编码了我们对图像的想象。AI交还给我们的,那些看似拥有惊人细节和不可思议的图像,并非真正的图像,而是语言的图像索引版本(往往是一堆概念的缝合、拼接和融合),是具有图像性的数据集合,是徒劳地对盲人解释何为颜色。
然而真正的危机是,尽管今天我们还会承认,米开朗基罗的工作不能被AI替代,但我们确实可以通过轻松地为语料库增加数据的方式,来训练一个AI,让它替代历史上真实的米开朗基罗。

米开朗基罗的“最新作品”,由Midjourney生成
每一个图像模型的公司都意识到了,只有人类创造的图像实例,才是世界本身的镜像。因此,开采图像实例,自然而然地成为了他们的终极使命所在。无论是Sora还是MJ,它们无一例外野心勃勃地宣称,自己要做的绝不仅仅是些文生图的小把戏,而是要彻底地、革命性地创建“世界模型” 。正如MJ的图生视频更新这样说:“正如你所知道的,过去几年我们的重点是图像。但你可能不知道,我们相信,这项技术最终将走向的,是能够模拟实时开放世界的模型。”(As you know, our focus for the past few years has been images. What you might not know, is that we believe the inevitable destination of this technology are models capable of real-time open-world simulations.)
一个实时、开放的世界模型,和我们所处的真实世界又能够有什么本质区别呢?这些硅谷公司似乎决心通过践行博尔赫斯的理想成为上帝,创造出一张能够覆盖全世界1:1的地图,用拟像覆盖全世界。更进一步的设想,是即便整个自然界不复存在,AI依然可以源源不断地生产出关于外部世界的新图像,我们终将进入信息总和远远大于自然总和的超真实世界。这在概念上是可能的,在技术上也正在实现。何况“虚拟”并非新问题,正如弗鲁塞尔所说,一张超真实的全息桌子,可以让人安然地把打字机安置其上。
于是,这一次,柏拉图洞穴中被缚的是AI,而我们,则成了那团映照世界的火。
相关文章

导致6名大学生溺亡,如何避免钢格栅板坠落?
上海市建设项目“开工一件事”工作方案发布

国话新版《物理学家》叩问人类良知和命运

艺术人物|石至莹:石海之间,对话与凝视

甘肃嘉峪关市委书记刘永升,调任贵州省国资委党委书记

一起互联网企业高管收受商业贿赂案被侦破:收受4000余万元,7人被抓

7月语言学联合书单|语言与文化依恋研究

李公明︱一周书记:没有一句正经话的……昆德拉

格筛板脱落致6名大学生溺亡,涉事企业今年曾更换部分格栅板

贵州贵阳市原市长马宁宇被双开:贪婪腐化,大搞权钱交易

印度恢复发放中国公民旅游签证,中印关系重回正轨还需多久?

国家医保局:今年1-6月全国共追回医保基金161.3亿元

6名大学生在企业参观学习溺亡,知情人:实习与毕业要求挂钩

复旦大学附属肿瘤医院召开干部大会,这三人职务有变化

无缘四强也已足够亮眼,年轻的中国女排有了迎接挑战的底气

专访|马伊琍:和创作者、观众“共建”那些鲜活的女性形象
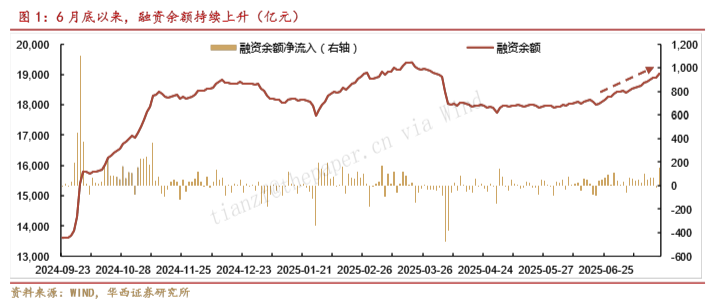
A股融资余额连续3个交易日超过1.9万亿元,意味着什么?

华南理工奖学金新规后续:学生已接通知延用原“全覆盖”政策
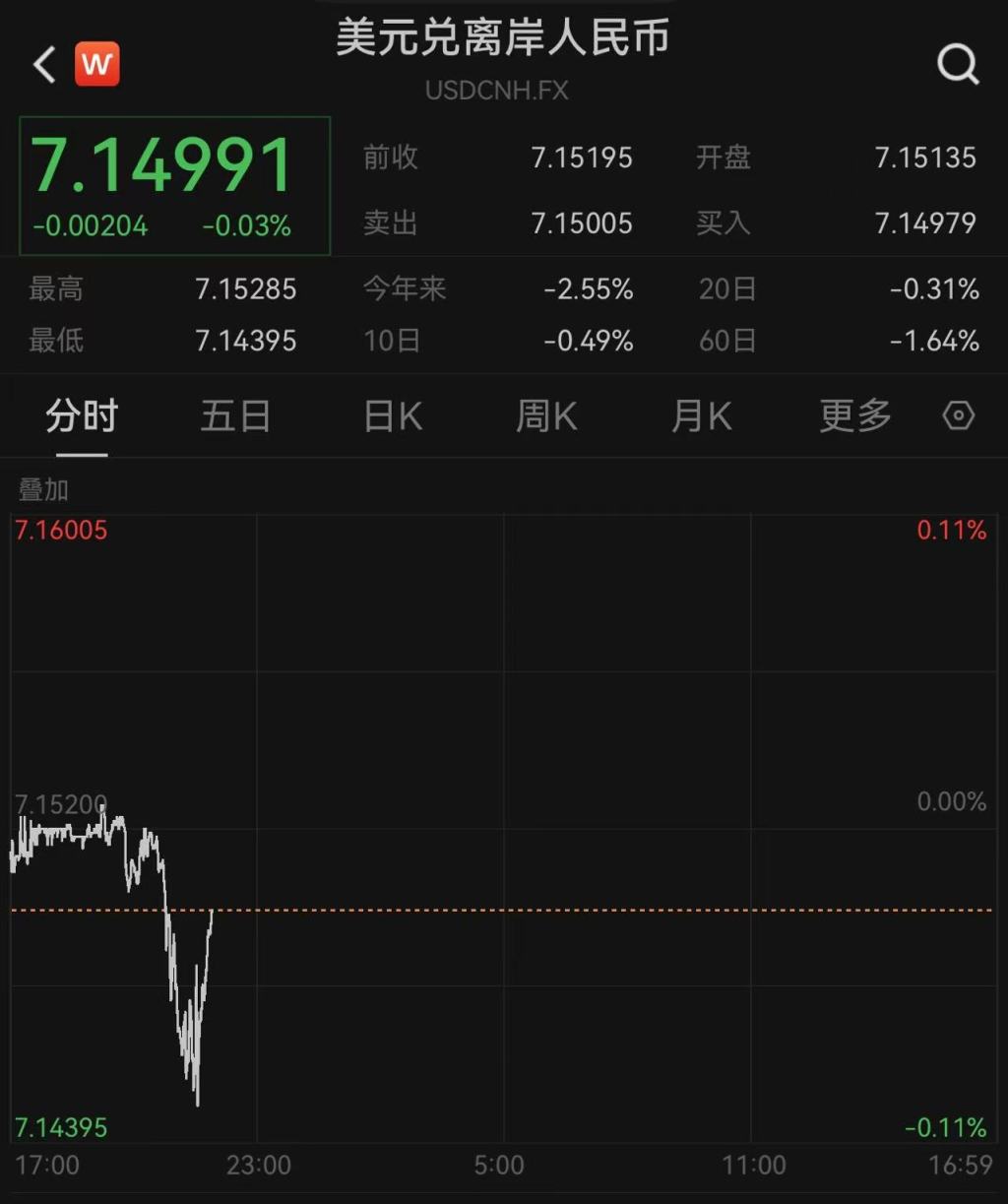
8个月新高,在岸、离岸人民币对美元汇率升破7.15关口
